Hi Friends,
I would like to start my new post in this year by wishing "HAPPY NEW YEAR".
Today I would like to share how to find out the reasons for the failover related to Availability Groups.
My Environment is like below. I am running on SQL Server 2017 RTM version and my operating system is WINDOWS 2012 R2.
I have 3 VMS one acting like DC and the other 2 nodes running on a multi subnet environment with file share witness as quorum.
Scenario 1: Manual Failover
When I was investigating the reasons for the failover I had difficulties to find out the root cause. But hopefully the below information might help others.
so when the failover has been initiated manually we can find it out from our error logs on SQL Server itself. I am not sure if the same messages gets logged in earlier versions of SQL but will share them if time permits.
NODE-1 is currently primary and I initiated failover from NODE-2 which is secondary. when you read your error log file on secondary you can find the below message.
The state of the local availability replica in availability group 'AGTEST' has changed from 'SECONDARY_NORMAL' to 'RESOLVING_PENDING_FAILOVER'. The state changed because of a user initiated failover.
The same can be find out from the cluster logs for any version of SQL below is the message for the same.
000005dc.00000888::2020/01/11-20:04:55.669 INFO [RCM] rcm::RcmApi::MoveGroup: (AGTEST, 2, 0, MoveType::Manual )
Scenario 2: Automatic Failover
This time we will reboot the primary node and see if we can find this any where from our logs.
There will not be any straight forward messages however my way of checking is if windows gets rebooted a new log would get created and you can see "RECOVERY" Messages for all the databases on the node that got rebooted.
From the cluster logs we can see the below message on the node which got rebooted
000005dc.0000060c::2020/01/11-20:29:32.218 INFO [CS] PreShutdown notification.
000005dc.0000060c::2020/01/11-20:29:32.218 INFO [CS] Service Stopping...
Also it is always advisable to check the reboot times of the nodes when ever fail over happens.
Scenario 3: Stopping the SQL Services on Primary
Before stopping the services I tried to Pause the SQL Service on primary but it didn't get failed over automatically. It says the service is in paused state and asked me to resume it.
When I stopped the Service the failover didn't happen automatically and the AG went into failed state and the secondary node is showing resolving.
I was little surprised but got to my basics back as in the above case since I rebooted the server now I exceeded my threshold and you can find this message inside the system logs of event viewer on primary.
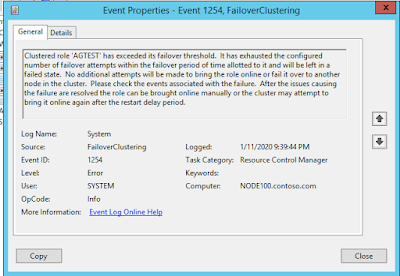
Then I increased the threshold level and performed the same operation this time the failover has happened as intended.

Now the real question comes how will you find out that failover has happened due to stoppage of services? Well, I found this tricky but when you check the Extended event Diagnostic files and observe it properly there is a message saying service is down. Also these files would run only on whomever is primary.
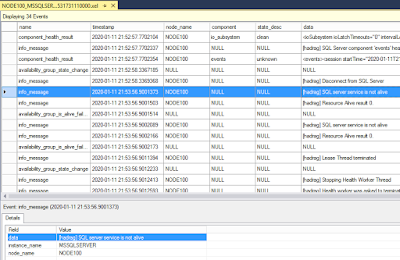
Scenario 4: Deadlock Schedulers
I tried really hard to reproduce this on my machine however I succeeded to certain extent. Usually a dump should get generated if this occurs.
These are the messages inside my error logs
2020-01-11 23:20:42.06 spid32s Error: 41009, Severity: 16, State: 3.
2020-01-11 23:20:42.06 spid32s The Windows Server Failover Clustering (WSFC) resource control API returned error code 5038. If this is a WSFC availability group, the WSFC service may not be running or may not be accessible in its current state, or the specified arguments are invalid. Otherwise, contact your primary support provider. For information about this error code, see "System Error Codes" in the Windows Development documentation.
2020-01-11 23:20:43.21 Server Stopped listening on virtual network name 'AGLISMULSUB10'. No user action is required.
2020-01-11 23:20:44.02 spid79 Always On: The local replica of availability group 'AGTEST' is preparing to transition to the resolving role. This is an informational message only. No user action is required.
2020-01-11 23:20:44.08 spid79 The state of the local availability replica in availability group 'AGTEST' has changed from 'PRIMARY_NORMAL' to 'RESOLVING_NORMAL'. The state changed because the availability group is going offline. The replica is going offline because the associated availability group has been deleted, or the user has taken the associated availability group offline in Windows Server Failover Clustering (WSFC) management console, or the availability group is failing over to another SQL Server instance. For more information, see the SQL Server error log or cluster log. If this is a Windows Server Failover Clustering (WSFC) availability group, you can also see the WSFC management console.
2020-01-11 23:20:44.08 Server The availability group 'AGTEST' is being asked to stop the lease renewal because the availability group is going offline. This is an informational message only. No user action is required.
2020-01-11 23:20:44.08 spid62s Always On Availability Groups connection with secondary database terminated for primary database 'AGTEST1' on the availability replica 'NODE300' with Replica ID: {bff310cb-b950-4db7-af29-b5d5d072624b}. This is an informational message only. No user action is required.
2020-01-11 23:20:50.75 spid31s The availability group database "AGTEST1" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2020-01-11 23:20:50.75 spid31s State information for database 'AGTEST1' - Hardened Lsn: '(42:6297:1)' Commit LSN: '(42:6272:2)' Commit Time: 'Jan 11 2020 9:53PM'
2020-01-11 23:20:50.75 spid31s Process ID 1865 was killed by an ABORT_AFTER_WAIT = BLOCKERS DDL statement on database_id = 5, object_id = 0.
2020-01-11 23:21:05.96 spid51 Always On: The local replica of availability group 'AGTEST' is preparing to transition to the primary role. This is an informational message only. No user action is required.
so if this happens you can check the availability group failover time and the dump generation time. In my case my failure level condition for AG instance is 3 which is default. After going through logs even though it didn't say the reason for the state change I could see the below.

I believe when we change the failure condition to level 5 then AG would get failed over to another node. Will try to perform the same and update you. Until then Happy Reading.
I would like to start my new post in this year by wishing "HAPPY NEW YEAR".
Today I would like to share how to find out the reasons for the failover related to Availability Groups.
My Environment is like below. I am running on SQL Server 2017 RTM version and my operating system is WINDOWS 2012 R2.
I have 3 VMS one acting like DC and the other 2 nodes running on a multi subnet environment with file share witness as quorum.
Scenario 1: Manual Failover
When I was investigating the reasons for the failover I had difficulties to find out the root cause. But hopefully the below information might help others.
so when the failover has been initiated manually we can find it out from our error logs on SQL Server itself. I am not sure if the same messages gets logged in earlier versions of SQL but will share them if time permits.
NODE-1 is currently primary and I initiated failover from NODE-2 which is secondary. when you read your error log file on secondary you can find the below message.
The state of the local availability replica in availability group 'AGTEST' has changed from 'SECONDARY_NORMAL' to 'RESOLVING_PENDING_FAILOVER'. The state changed because of a user initiated failover.
The same can be find out from the cluster logs for any version of SQL below is the message for the same.
000005dc.00000888::2020/01/11-20:04:55.669 INFO [RCM] rcm::RcmApi::MoveGroup: (AGTEST, 2, 0, MoveType::Manual )
Scenario 2: Automatic Failover
This time we will reboot the primary node and see if we can find this any where from our logs.
There will not be any straight forward messages however my way of checking is if windows gets rebooted a new log would get created and you can see "RECOVERY" Messages for all the databases on the node that got rebooted.
From the cluster logs we can see the below message on the node which got rebooted
000005dc.0000060c::2020/01/11-20:29:32.218 INFO [CS] PreShutdown notification.
000005dc.0000060c::2020/01/11-20:29:32.218 INFO [CS] Service Stopping...
Also it is always advisable to check the reboot times of the nodes when ever fail over happens.
Scenario 3: Stopping the SQL Services on Primary
Before stopping the services I tried to Pause the SQL Service on primary but it didn't get failed over automatically. It says the service is in paused state and asked me to resume it.
When I stopped the Service the failover didn't happen automatically and the AG went into failed state and the secondary node is showing resolving.
I was little surprised but got to my basics back as in the above case since I rebooted the server now I exceeded my threshold and you can find this message inside the system logs of event viewer on primary.

Then I increased the threshold level and performed the same operation this time the failover has happened as intended.

Now the real question comes how will you find out that failover has happened due to stoppage of services? Well, I found this tricky but when you check the Extended event Diagnostic files and observe it properly there is a message saying service is down. Also these files would run only on whomever is primary.

Scenario 4: Deadlock Schedulers
I tried really hard to reproduce this on my machine however I succeeded to certain extent. Usually a dump should get generated if this occurs.
These are the messages inside my error logs
2020-01-11 23:20:42.06 spid32s Error: 41009, Severity: 16, State: 3.
2020-01-11 23:20:42.06 spid32s The Windows Server Failover Clustering (WSFC) resource control API returned error code 5038. If this is a WSFC availability group, the WSFC service may not be running or may not be accessible in its current state, or the specified arguments are invalid. Otherwise, contact your primary support provider. For information about this error code, see "System Error Codes" in the Windows Development documentation.
2020-01-11 23:20:43.21 Server Stopped listening on virtual network name 'AGLISMULSUB10'. No user action is required.
2020-01-11 23:20:44.02 spid79 Always On: The local replica of availability group 'AGTEST' is preparing to transition to the resolving role. This is an informational message only. No user action is required.
2020-01-11 23:20:44.08 spid79 The state of the local availability replica in availability group 'AGTEST' has changed from 'PRIMARY_NORMAL' to 'RESOLVING_NORMAL'. The state changed because the availability group is going offline. The replica is going offline because the associated availability group has been deleted, or the user has taken the associated availability group offline in Windows Server Failover Clustering (WSFC) management console, or the availability group is failing over to another SQL Server instance. For more information, see the SQL Server error log or cluster log. If this is a Windows Server Failover Clustering (WSFC) availability group, you can also see the WSFC management console.
2020-01-11 23:20:44.08 Server The availability group 'AGTEST' is being asked to stop the lease renewal because the availability group is going offline. This is an informational message only. No user action is required.
2020-01-11 23:20:44.08 spid62s Always On Availability Groups connection with secondary database terminated for primary database 'AGTEST1' on the availability replica 'NODE300' with Replica ID: {bff310cb-b950-4db7-af29-b5d5d072624b}. This is an informational message only. No user action is required.
2020-01-11 23:20:50.75 spid31s The availability group database "AGTEST1" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
2020-01-11 23:20:50.75 spid31s State information for database 'AGTEST1' - Hardened Lsn: '(42:6297:1)' Commit LSN: '(42:6272:2)' Commit Time: 'Jan 11 2020 9:53PM'
2020-01-11 23:20:50.75 spid31s Process ID 1865 was killed by an ABORT_AFTER_WAIT = BLOCKERS DDL statement on database_id = 5, object_id = 0.
2020-01-11 23:21:05.96 spid51 Always On: The local replica of availability group 'AGTEST' is preparing to transition to the primary role. This is an informational message only. No user action is required.
so if this happens you can check the availability group failover time and the dump generation time. In my case my failure level condition for AG instance is 3 which is default. After going through logs even though it didn't say the reason for the state change I could see the below.

I believe when we change the failure condition to level 5 then AG would get failed over to another node. Will try to perform the same and update you. Until then Happy Reading.
Comments