Hi Friends,
As we know Performance is one area where the scope for learning will never end. Today I am going to share an article which emphasizes on Seek/Scan and Sort operators. There are many blogs and my article is nothing in front of them but I am just sharing the knowledge of what I could.
Let me start up with the demo first. We have 2 tables one containing LogID and other some random Dates. When it comes to second table as you can see it has PK/FK relationship on the column LogID and a userid column which has only 3 users (1,2,3).
CREATE TABLE [dbo].[LogTable]
(
[LogID] [int] NOT NULL IDENTITY(1, 1) ,
[DateSent] [datetime] NULL,
)
ON [PRIMARY]
GO
ALTER TABLE [dbo].[LogTable] ADD CONSTRAINT [PK_LogTable] PRIMARY KEY CLUSTERED ([LogID]) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_LogTable_DateSent] ON [dbo].[LogTable] ([DateSent] DESC) ON [PRIMARY]
GO
CREATE TABLE [dbo].[LogTable_Cross]
(
[LogID] [int] NOT NULL ,
[UserID] [int] NOT NULL
)
ON [PRIMARY]
GO
ALTER TABLE [dbo].[LogTable_Cross] WITH NOCHECK ADD CONSTRAINT [FK_LogTable_Cross_LogTable] FOREIGN KEY ([LogID]) REFERENCES [dbo].[LogTable] ([LogID])
GO
CREATE NONCLUSTERED INDEX [IX_LogTable_Cross_UserID_LogID]
ON [dbo].[LogTable_Cross] ([UserID])
INCLUDE ([LogID])
GO
INSERT INTO [LogTable]
SELECT TOP 100000
DATEADD(day, ( ABS(CHECKSUM(NEWID())) % 65530 ), 0)
FROM sys.sysobjects
CROSS JOIN sys.all_columns
INSERT INTO [LogTable_Cross] SELECT [LogID] ,1 FROM [LogTable] ORDER BY NEWID()
INSERT INTO [LogTable_Cross] SELECT [LogID] ,2 FROM [LogTable] ORDER BY NEWID()
INSERT INTO [LogTable_Cross] SELECT [LogID] ,3 FROM [LogTable] ORDER BY NEWID()
GO
I will show you top 5 rows (in descending order) in each of the tables

As you can see from the script above we have clustered index on logID column and non clustered index on Datesent column for the Logtable. when it comes to other table we have non clustered index on LogID with included column as userid.
Now I want to select all those logs (from LogTable) which has given userid (user id will be checked from cross table LogTable_Cross) with datesent desc.
SELECT DI.LogID
FROM LogTable DI
INNER JOIN LogTable_Cross DP ON DP.LogID = DI.LogID
WHERE DP.UserID = 1
ORDER BY DateSent DESC

If you see from the execution plan it went for Clustered Index Scan on LogTable and seek on LogTable_cross. It went for parallel execution plan and when it comes to Cost it is Sort operation which is consuming 45 %.
Let's execute the same query but this time with MAXDOP 1 and see if there is any change with respect to sort operation.


When it comes to scans the database engine has 2 options.
1)Allocation Ordered Scans
2)Index Order Scan
When the plan shows a Table Scan operator, the storage engine has only one option: to use an allocation order scan. When the plan shows an Index Scan operator (clustered or nonclustered) with the property Ordered: True, the storage engine can use only an index order scan.
When the plan shows an Index Scan operator with Ordered: False, the relational engine doesn’t care in what order the rows are returned. In this case, there are two options to scan the data: allocation order scan and index order scan. It is up to the storage engine to determine which to employ.
In the above execution plan it opted for False which means it went for allocation ordered scan. As the order is false it has to go with Hash join. If it would have been true then definitely we will have Merge join operator.
Okay now in both plans (parallel and Serial) it is suggesting an missing index so let's create one and see if that eliminates sort operator.
We have an index with userid as the leading column and the missing index is suggesting to create leading column as LogID and then userID.
After creating the index I tried running the same query and I got the below execution plans for parallel and serial(maxdop 1)
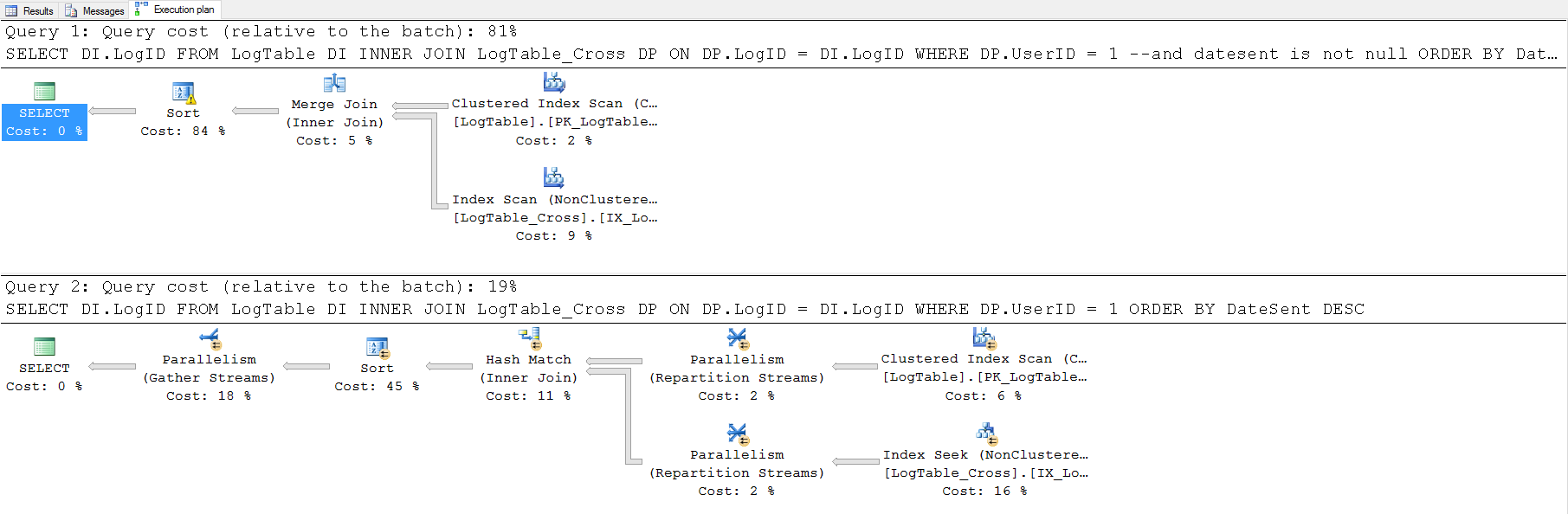
So the top execution plan is for serial execution and the bottom for parallel. If you notice there is no change in the plan when it comes to parallel execution and for serial as explained above this time we got Merge join operator instead of Hash as now ordered property is true. Also it made use of the index what missing index has requested and it went with Index scan instead of seek.

Okay if you compare the costs the one with parallel outcomes the serial as it is just 19%.
Now back to my question the sort operator is there even now and it is the one which is contributing to the cost so how to get rid of this?
Well when I forced the optimizer to make use of nested joins then the sort operator got disappeared.
SELECT DI.LogID
FROM LogTable DI
INNER JOIN LogTable_Cross DP ON DP.LogID = DI.LogID
WHERE DP.UserID = 1
ORDER BY DateSent DESC
OPTION (MAXDOP 1, LOOP JOIN);



Comments